Jenkins-as-Code Part I | Initial Setup
This is the beginning of a series about full Jenkins automation. I am calling that approach jenkins-as-code. The goal is to configure every aspect of Jenkins and its pipelines from a central git repository. We will leverage groovy scripting, jobDSL and shared libraries to not only codify the build/deploy pipelines (pipeline-as-code), but to also bootstrap and configure Jenkins from scratch (e.g., credentials, authorization, theme and job setup).
The following demo shows what we have at the end of this series:
Every aspect of what is shown here can be found in full context in the jenkins-as-code Github repository.
It is usually a good idea to have as much as possible setup in an *-as-code approach, because it offers:
- clear definitions and automation, i.e., clear state definition and reproducibility
- rollouts from central servers (offers audit logs)
- common software development workflows, i.e., testing, reviewing and rollouts are easier to manage
Since Jenkins 2.x we can use pipeline-as-code approaches like Travis or CircleCI do. However, the overall (plugin) configuration and setup of job interfaces is not covered by pipeline-as-code. For a complete jenkins-as-code approach we also want our configuration and job interfaces treated as-code and be able to rollout any changes dynamically through a jenkins job interface without the need to restart Jenkins.
In the first part of this series we will discuss the basics:
- What are the layers in jenkins-as-code?
- What are the relations between those layers?
Next, we will create a Jenkins docker image packaged with a configuration/seeding job interface and pipeline definition, which uses a central shared library from GitHub to rollout configuration and seeding changes. Finally, we will have a closer look at contents of that central shared library.
Layers and Terminology
In order to avoid confusion it is very important to define the different layers and terms which will be used throughout this series.
Jenkins-as-Code
Jenkins-as-code describes an approach to codify and automate every layer of Jenkins. In order to achieve its goal the approach leverages jobDSL, configuration and pipeline definition scripts.
Job Interface
A job interface describes the job in the Jenkins UI. Deep down a job interface is xml on the Jenkins master instance, usually found at ${JENKINS_HOME}/jobs. We use a job interface to declare input parameters and to trigger the job. Preferably, a job interface is created using the Jenkins jobDSL plugin. When a job is triggered it loads the pipeline definition.
Pipeline Definition
A pipeline definition is a groovy script which is loaded by a job interface when a job is triggered. Those groovy scripts are also known as pipeline-as-code - an approach also known from cloud CIs like Travis or CircleCI.
Configuration Script
A configuration script is a system groovy script, which interacts with the Jenkins eco-system to configure Jenkins and its plugins.
CasC
[C]onfiguration [as] [C]ode refers to the Configuration-as-Code Plugin. Rather than writing configuration scripts, this plugin allows to define your configuration in a simple .yaml syntax.
JobDSL Script
A jobDSL script is a groovy script which programmatically describes job interfaces. It is read by the Jenkins jobDSL plugin to create the job interfaces.
Seeding
Seeding refers to creating all job interfaces from a single pipeline (the seeding job). That pipeline executes the jobDSL scripts in order to create all job interfaces.
Layers and their Interaction
Layers in jenkins-as-code: 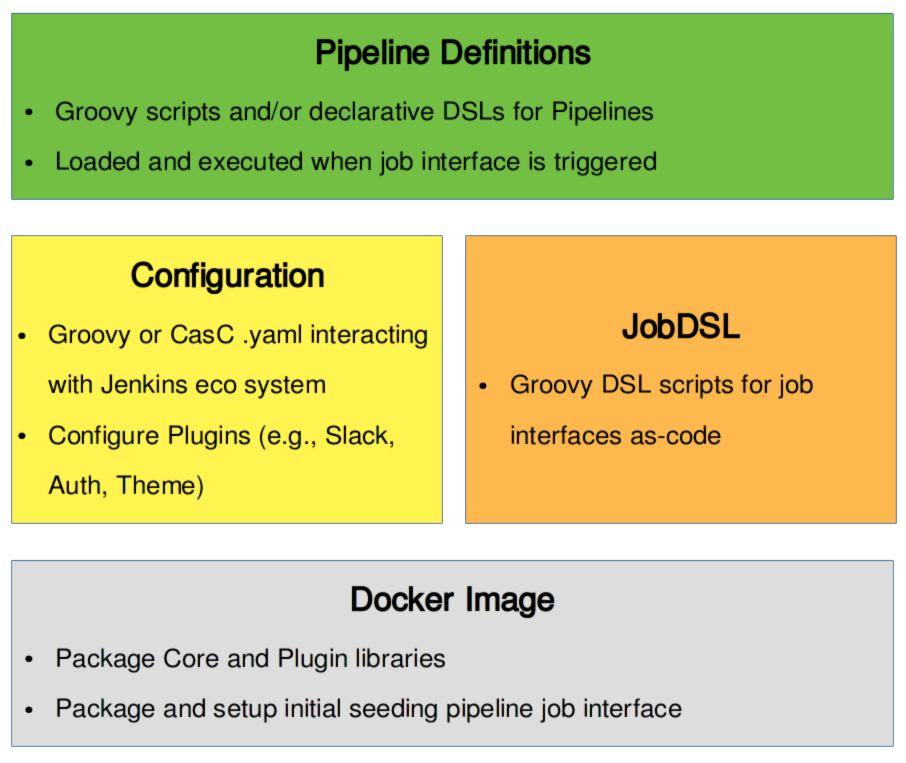
Interaction between the layers: 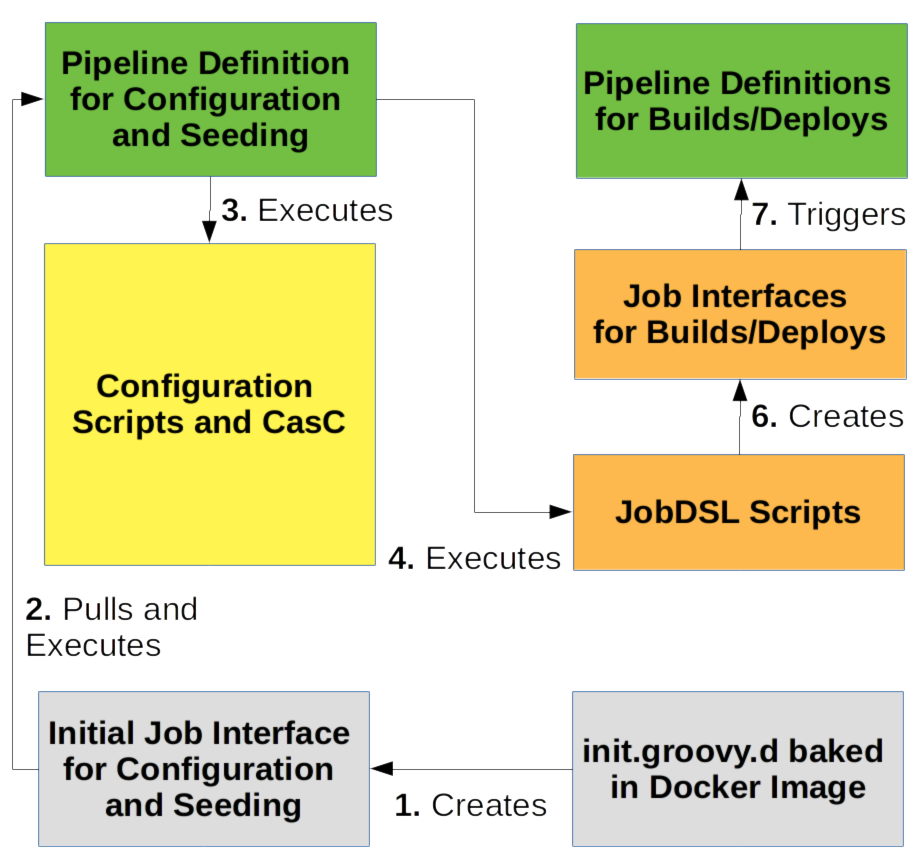
Jenkins Docker Image
Now that we have covered some basics, let us begin with the hands-on work and create a docker image for our Jenkins.
Directory Structure
We will use the following directory structure:
docker/
|-- Dockerfile
|-- dsl
| `-- ConfigurationAndSeedingPipelineDSL.groovy
|-- init.groovy.d
| `-- init.groovy
`-- plugins.txt
The following sub-sections show the files in detail.
Dockerfile and Plugins
We want to build an image which automatically bootstraps our Jenkins with an initial job interface for configuration and seeding.
Dockerfile:
NOTE: That Dockerfile also installs HashiCorp’s Vault. While it is not needed in this part of the series we install it anyways for later use.
Also, we must ensure that some plugins are installed.
plugins.txt:
Most of those plugins are not necessary at this step of the series, but might come in handy later on.
NOTE: Plugin versions are not pinned here as this is a demo. However, I recommend to pin the plugin versions inside the plugins.txt in order to have deterministic docker image builds.
Initial Pipeline Interface
The seed and configuration job interface is created through a jobDSL script.
ConfigurationAndSeedingPipelineDSL.groovy:
init.groovy.d for initial setup
init.groovy.d is a directory in the jenkins home directory, which contains configuration scripts. Configuration scripts inside that directory are executed in alphabetical order at Jenkins boot time. This is ideal for setting up seeding and configuration job interfaces.
init.groovy:
This script first adds a SSH private deploy key to Jenkins with access permissions to the shared library repository. Further, the script creates a configuration and seed job from a jobDSL script. That job will be used to pull the shared library from git and rollout its configuration and jobDSL definitions.
NOTE: The script assumes that the SSH key is already created and mounted into the docker container. The corresponding public key must be uploaded to GitHub as a deploy key for the shared library repository in order for Jenkins to pull it.
When you build this docker image and start the container, init.groovy.d will add your (mounted) SSH deploy key and create the configuration and seeding job interface. When this interface is triggered, it will load the central shared library and run our pipeline defintions.
Shared Library Repository
Lets have a look now at how our shared jenkins library looks like.
Directory Structure
We will use the following directory structure for our shared library:
shared-library
|-- resources
| |-- config
| | |-- configuration-as-code-plugin
| | | `-- jenkins.yaml
| | `-- groovy
| | |-- timezone.groovy
| | |-- triggerConfigurationAsCodePlugin.groovy
| | `-- userPublicKeys.groovy
| |-- init
| | `-- ConfigurationAndSeedingPipeline.groovy
| `-- jobDSL
`-- vars
The vars directory will contain our job pipeline (build/deploy). Those pipelines will be called from a Jenkinsfile inside one of our projects, but we will focus on that in a later part of this series and can leave it empty. Also the resources/jobDSL directory which is intended for job definitions will be left out for now. We will come back to in a later part of this series. For now we focus on the resources/init and resources/config directories. resources/init holds initial configuration and seeding pipelines which leverage scripts in resources/config and resources/jobDSL to configure and seed jobs.
In addition, we need a configuration and seeding pipeline script in the shared library repository.
ConfigurationAndSeedingPipeline.groovy:
The scripts loaded and executed in this job definition, e.g., triggerConfigurationAsCodePlugin.groovy or timezone.groovy are discussed in the next part of this jenkins-as-code series.
Summary
We now have a pipeline definition for configuration and seeding. That pipeline defintion is triggered by an initial job interface for configuration and seeding. The initial job interface is bootstrapped by our docker image (init.groovy.d).
The next part of the jenkins-as-code series will focus on the configuration scripts, e.g., OAuth authentication, theming, slack and credentials.
I use disqus as a comment system. If you click on the following button, then the disqus comment system will load in your browser and you agree to the disqus privacy policy. To delete your data from disqus you can contact their support team directly.